#T-SQL to find if
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s website traffic is steadily declining.
Text
I'm very good at "professionalism" I was trained from a young age. If I get an interview, I'm getting the job. I sit upright in my chair and wear a collared shirt and my employer thinks, "wow! She has a lot of passion for this role!" Buddy, you don't know the start of it. You don't even know my gender.
I'm OSHA certified. I got my 24-hour GD&T training. They can see this. What they don't see is me waxing poetical about surface finish or some shit on this website. When I was in 6th grade, I was exposed to Autodesk Inventor and it changed me fundamentally as a person. Whenever I look at any consumer good (of which there are a lot) I have to consider how it was made. And where the materials came from and how it got here and really the whole ass process. It's fascinating to me in a way that can be described as "intense". I love looking at large machines and thinking about them and taking pictures of them. There are so many steps and machines and people involved to create anything around you. I think if any person truly understood everything that happened in a single factory they would go insane with the knowledge. But by god am I trying. My uncle works specifically on the printers that print dates onto food. There are hundreds or even thousands of hyperspecific jobs like that everywhere. My employer looks away and I'm creating an unholy abomination of R and HTML, and I'm downloading more libraries so I can change the default CSS colors. I don't know anything about programming but with the power of stack overflow and sheer determination I'm making it happen. Is it very useful? No. But I'm learning a lot and more importantly I don't give a fuck. I'm learning about PLCs. I'm learing about CNC machines. I'm fucking with my laptop. I'm deleting SQL databases. I'm finding electromechanical pinball machines on facebook marketplace. I'm writing G-code by hand. I'm a freight train with no brakes. I'm moving and I'm moving fast. And buddy, you better hope I'm moving in the right direction. I must be, because all of my former employers give me stellar reviews when used as a reference. I'm winning at "career" and also in life.
14 notes
·
View notes
Text
Top 5 Selling Odoo Modules.
In the dynamic world of business, having the right tools can make all the difference. For Odoo users, certain modules stand out for their ability to enhance data management and operations. To optimize your Odoo implementation and leverage its full potential.
That's where Odoo ERP can be a life savior for your business. This comprehensive solution integrates various functions into one centralized platform, tailor-made for the digital economy.
Let’s drive into 5 top selling module that can revolutionize your Odoo experience:
Dashboard Ninja with AI, Odoo Power BI connector, Looker studio connector, Google sheets connector, and Odoo data model.
1. Dashboard Ninja with AI:
Using this module, Create amazing reports with the powerful and smart Odoo Dashboard ninja app for Odoo. See your business from a 360-degree angle with an interactive, and beautiful dashboard.
Some Key Features:
Real-time streaming Dashboard
Advanced data filter
Create charts from Excel and CSV file
Fluid and flexible layout
Download Dashboards items
This module gives you AI suggestions for improving your operational efficiencies.
2. Odoo Power BI Connector:
This module provides a direct connection between Odoo and Power BI Desktop, a Powerful data visualization tool.
Some Key features:
Secure token-based connection.
Proper schema and data type handling.
Fetch custom tables from Odoo.
Real-time data updates.
With Power BI, you can make informed decisions based on real-time data analysis and visualization.
3. Odoo Data Model:
The Odoo Data Model is the backbone of the entire system. It defines how your data is stored, structured, and related within the application.
Key Features:
Relations & fields: Developers can easily find relations ( one-to-many, many-to-many and many-to-one) and defining fields (columns) between data tables.
Object Relational mapping: Odoo ORM allows developers to define models (classes) that map to database tables.
The module allows you to use SQL query extensions and download data in Excel Sheets.
4. Google Sheet Connector:
This connector bridges the gap between Odoo and Google Sheets.
Some Key features:
Real-time data synchronization and transfer between Odoo and Spreadsheet.
One-time setup, No need to wrestle with API’s.
Transfer multiple tables swiftly.
Helped your team’s workflow by making Odoo data accessible in a sheet format.
5. Odoo Looker Studio Connector:
Looker studio connector by Techfinna easily integrates Odoo data with Looker, a powerful data analytics and visualization platform.
Some Key Features:
Directly integrate Odoo data to Looker Studio with just a few clicks.
The connector automatically retrieves and maps Odoo table schemas in their native data types.
Manual and scheduled data refresh.
Execute custom SQL queries for selective data fetching.
The Module helped you build detailed reports, and provide deeper business intelligence.
These Modules will improve analytics, customization, and reporting. Module setup can significantly enhance your operational efficiency. Let’s embrace these modules and take your Odoo experience to the next level.
Need Help?
I hope you find the blog helpful. Please share your feedback and suggestions.
For flawless Odoo Connectors, implementation, and services contact us at
[email protected] Or www.techneith.com
#odoo#powerbi#connector#looker#studio#google#microsoft#techfinna#ksolves#odooerp#developer#web developers#integration#odooimplementation#crm#odoointegration#odooconnector
4 notes
·
View notes
Text
My Dev VM

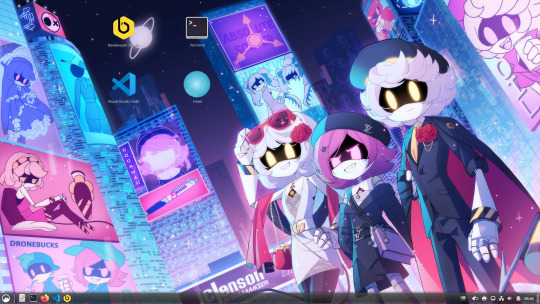
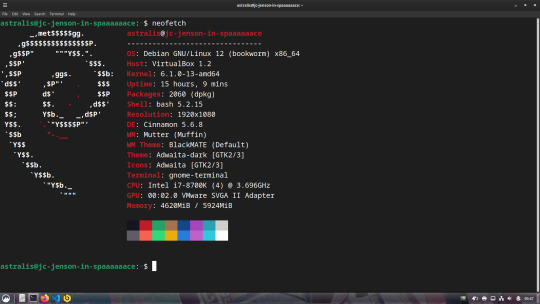
For those interested, this is what my dev machine looks like. Debian 12 + Cinnamon Desktop running inside of Virtual Box
The wallpaper is one I found on DA, but from what I can tell I don't think that the uploader was the original artist, especially after looking through the uploader's gallery. I have tried to find the original to no avail (TinEye, Lens, etc), so if someone finds the original artist I'd be more than grateful (and willing to shoot a few pounds their way cuz this piece is amazing)
Outside of that, I use VSCode most of the time on Linux, Komodo Edit (RIP T^T) on Windows, Beekeeper for SQL (database stuff) on Linux and Heidi on Windows, and Bash on Linux and Powershell on Windows for terminal/scripting.
For languages, it changes between three, Node/JS for web apps, C# for the majority of game and Windows stuff, and Elixir/Erlang (Oh look my MD OC's last name) for more random stuff cuz I'm trying to learn it.
So yea, thats my nerdy infodump for the moment, I do still create random website designs in my downtime after work but more often than not, I just play copious amounts of Trackmania and FFXIV.
4 notes
·
View notes
Text
I don't really think they're like, as useful as people say, but there are genuine usecases I feel -- just not for the massive, public facing, plagiarism machine garbage fire ones. I don't work in enterprise, I work in game dev, so this goes off of what I have been told, but -- take a company like Oracle, for instance. Massive databases, massive codebases. People I know who work there have told me that their internally trained LLM is really good at parsing plain language questions about, say, where a function is, where a bit oif data is, etc., and outputing a legible answer. Yes, search machines can do this too, but if you've worked on massive datasets -- well, conventional search methods tend to perform rather poorly.
From people I know at Microsoft, there's an internal-use version of co-pilot weighted to favor internal MS answers that still will hallucinate, but it is also really good at explaining and parsing out code that has even the slightest of documentation, and can be good at reimplementing functions, or knowing where to call them, etc. I don't necessarily think this use of LLMs is great, but it *allegedly* works and I'm inclined to trust programmers on this subject (who are largely AI critical, at least wrt chatGPT and Midjourney etc), over "tech bros" who haven't programmed in years and are just execs.
I will say one thing that is consistent, and that I have actually witnessed myself; most working on enterprise code seem to indicate that LLMs are really good at writing boilerplate code (which isn't hard per se, bu t extremely tedious), and also really good at writing SQL queries. Which, that last one is fair. No one wants to write SQL queries.
To be clear, this isn't a defense of the "genAI" fad by any means. chatGPT is unreliable at best, and straight up making shit up at worst. Midjourney is stealing art and producing nonsense. Voice labs are undermining the rights of voice actors. But, as a programmer at least, I find the idea of how LLMs work to be quite interesting. They really are very advanced versions of old text parsers like you'd see in old games like ZORK, but instead of being tied to a prewritten lexicon, they can actually "understand" concepts.
I use "understand" in heavy quotes, but rather than being hardcoded to relate words to commands, they can connect input written in plain english (or other languages, but I'm sure it might struggle with some sufficiently different from english given that CompSci, even tech produced out of the west, is very english-centric) to concepts within a dataset and then tell you about the concepts it found in a way that's easy to parse and understand. The reason LLMs got hijacked by like, chatbots and such, is because the answers are so human-readable that, if you squint and turn your head, it almost looks like a human is talking to you.
I think that is conceptually rather interesting tech! Ofc, non LLM Machine Learning algos are also super useful and interesting - which is why I fight back against the use of the term AI. genAI is a little bit more accurate, but I like calling things what they are. AI is such an umbrella that includes things like machine learning algos that have existed for decades, and while I don't think MOST people are against those, I see people who see like, a machine learning tool from before the LLM craze (or someone using a different machine learning tool) and getting pushback as if they are doing genAI. To be clear, thats the fault of the marketing around LLMs and the tech bros pushing them, not the general public -- they were poorly educated, but on purpose by said PR lies.
Now, LLMs I think are way more limited in scope than tech CEOs want you to believe. They aren't the future of public internet searches (just look at google), or art creation, or serious research by any means. But, they're pretty good at searching large datasets (as long as there's no contradictory info), writing boilerplate functions, and SQL queries.
Honestly, if all they did was SQL queries, that'd be enough for me to be interested fuck that shit. (a little hyperbolic/sarcastic on that last part to be clear).
ur future nurse is using chapgpt to glide thru school u better take care of urself
154K notes
·
View notes
Text
Analyst Roles in Kolkata's Textile Sector
Renowned for its vibrant cultural legacy and artistic flair, Kolkata has traditionally served as a major center for the textile and garment industry. From handcrafted fabrics to large-scale manufacturing units, the city plays a vital role in India’s textile economy. As the sector increasingly embraces digitization and data-driven decision-making, the demand for data analysts in Kolkata’s textile industry is growing rapidly. Businesses today require actionable insights to optimize production, monitor supply chains, understand consumer trends, and improve profitability. This shift has opened up exciting new career avenues for aspiring analysts in the region.
The Evolving Role of Data Analysts in the Textile Industry
Traditionally, the textile industry relied on manual methods and intuition for decision-making. However, with growing competition, rising raw material costs, and fluctuating consumer demand, companies now recognize the importance of data. Data analysts help bridge this gap by collecting, organizing, and interpreting data to reveal patterns and provide insights that drive smarter strategies.
In the textile sector, data analysts play a wide range of roles including:
Forecasting demand for different product lines and seasonal trends.
Analyzing production efficiency and minimizing material wastage.
Monitoring supply chain logistics and identifying bottlenecks.
Evaluating customer feedback to improve product design and quality.
Assisting management with sales data, pricing decisions, and inventory planning.
With more organizations adopting ERP systems and digital tracking tools, the need for skilled data professionals has never been greater.
The Growing Opportunity in Kolkata
As one of India’s major textile markets, Kolkata is home to numerous manufacturers, exporters, and retailers who are increasingly hiring analysts to modernize their operations. From legacy businesses in Burrabazar to modern textile parks on the city’s outskirts, the need for data insight is universal.
For aspiring professionals, this growth means a steady increase in internship and job opportunities—provided you have the right skillset. Pursuing data analyst training in Kolkata can help bridge the gap between raw talent and employability, especially when it’s tailored to industry-relevant tools and techniques.
Importance of Professional Training
The pathway to becoming a successful analyst begins with structured learning. Whether you come from a commerce, science, or even a design background, enrolling in one of the best data analyst courses can fast-track your journey. These programs typically cover:
Core programming languages like Python or R.
Data manipulation using Excel, SQL, and databases.
Statistical methods and data visualization.
Real-world case studies and capstone projects.
Beyond technical knowledge, a good course also equips learners with problem-solving skills, business acumen, and communication strategies—all of which are essential in a practical work environment.
Why Offline Learning Still Matters
While online learning is popular, many students and working professionals still prefer offline classes for the added structure, peer interaction, and direct mentorship they offer. A well-organized offline program provides the environment for focused study and real-time feedback from instructors. For learners based in West Bengal, finding institutes that offer hands-on, instructor-led data analyst training in Kolkata can be a decisive advantage in gaining both confidence and clarity in core concepts.
Offline learning also fosters stronger networking, group discussions, and collaborative projects—skills that are incredibly valuable in real-world analyst roles.
DataMites Institute – A Trusted Partner in Your Data Journey
When it comes to launching a successful career in analytics, choosing the right training provider is crucial. DataMites has earned a reputation for delivering industry-aligned courses that prepare learners for real-world challenges. Whether you’re a beginner or someone seeking a career transition, DataMites Institute offers a well-rounded curriculum designed to build technical skills, domain knowledge, and practical experience.
Endorsed by IABAC and NASSCOM FutureSkills, DataMites Institute offers courses that adhere to international industry standards. Learners benefit from expert guidance, practical project experience, internship programs, and extensive placement support.
DataMites Institute also provides offline classroom training in major cities like Mumbai, Pune, Hyderabad, Chennai, Delhi, Coimbatore, and Ahmedabad—ensuring accessible and flexible learning opportunities throughout India. For learners in Pune, DataMites Institute offers an excellent platform to master Python and succeed in today’s fast-paced tech landscape.
For students and professionals in Kolkata, DataMites Institute offers a strong foundation in data analytics with a curriculum that includes practical case studies relevant to sectors like textiles, manufacturing, and retail. The institute’s structured training, placement assistance, and internship programs make it one of the most reliable options for those looking to build a future in analytics.
Kolkata’s textile industry is at a crossroads—blending heritage with modern technology. As data continues to shape the way decisions are made, the need for skilled analysts will only grow. By investing in the best data analyst courses and choosing the right learning path, you can position yourself at the forefront of this transformation.
Whether your goal is to join a heritage textile firm or a fast-paced export house, building your data skills through quality education—such as what DataMites provides—can set you on the path to a meaningful and future-ready career.
0 notes
Text
QA Engineers || IT Company || Bank || Kolkata || West Bengal || India || World
Unlock Your Dream Job!
In this Job Post, we dive into the "Ideal Career Zone," revealing the secrets to finding your perfect profession!
Whether you’re hunting for a #job, searching #Naukri, or exploring new #Chakri options, we’ve got you covered with expert tips and career advice. From understanding your passions to mastering job searches and acing interviews, we empower you to navigate the competitive landscape with confidence!
Join us and discover how to elevate your career journey today!
Company Introduction:
A Global I T company head office in Bangalore they will work with you to make it a reality and enable you to deliver digital delight to your global customers. The digital age demands the strategy and execution that is relevant to the times, resilient to changes and drive ROI. Their solutions bring you a unique balance of strategy design and execution capability to realize your digital dreams.
Please find the attached JD for QA Engineers for Kolkata Location.
The experience range is 1 to 3 years and 3 to 5 years.
The Maximum budget for 1 to 3 years is 6 LPA and 3 to 5 years is 7.5 LPA.
Now they are looking for candidates who have the exposure into Loan Management System/ Loan Orientation Systems . Immediate Joiners are preferred
Job Description for QA Engineer
Location: Kolkata
We are seeking highly skilled Testing Specialists to support the Sales force implementation for loan origination processes. The ideal candidates will have expertise in functional, integration, regression, and User Acceptance Testing (UAT) across Sales force and Flex cube LMS. They will work collaboratively with business analysts, developers, and configuration teams to ensure seamless system behavior and optimal performance.
Key Responsibilities:
Validate and analyze the complete Loan Origination lifecycle, including lead capture, application processing, credit evaluation, approval workflows, disbursements, and system handoffs to Flex cube LMS.
Design and execute test plans, test cases, and test scripts for Sales force-based origination workflows and Flex cube integrations.
Conduct functional, integration, regression, and UAT testing for housing loan journeys across Sales force and Flex cube.
Verify critical components of the origination process, including:
Customer on boarding (KYC, eligibility verification).
Loan application creation, submission, and processing.
Document collection and validation.
Credit appraisal, approval, and final disbursement workflows in Flex cube LMS.
Validate data synchronization, integration points, and system interactions between Sales force and Flex cube.
Perform backend validations using SQL queries and investigate potential issues using logs or APIs.
Log, track, and manage defect resolution using standard test management tools (e.g., SPIRA, JIRA, Test Rail, HP ALM).
Collaborate closely with developers, business analysts, Sales force consultants, and Flex cube configuration teams to ensure system integrity and business requirement alignment.
Required Skills & Qualifications:
Hands-on experience in testing Sales force-based workflows and Flex cube LMS integrations.
Strong understanding of the loan origination process and associated financial systems.
Proficiency in SQL queries, API validations, and backend data integrity checks.
Experience with defect tracking and standard test management tools (SPIRA, JIRA, Test Rail, HP ALM).
Excellent problem-solving and analytical skills.
Ability to work collaboratively in a fast-paced project-driven environment.
Preferred Qualifications:
Prior experience in banking and financial sector testing.
Knowledge of Sales force ecosystem and Flex cube LMS configurations.
Interested candidates are most welcome to apply with their updated resumes at – [email protected] and please you must mentioned post which you wish to apply or call HR: 9331205133
* Note:- You can find many more job details in various posts in various companies.
You may call us between 9 am to 8 pm
8 7 7 7 2 1 1 zero 1 6
9 3 3 1 2 zero 5 1 3 3
Or you can visit our office.
Ideal Career Zone
128/12A, BidhanSraniShyam Bazaar metro Gate No.1 Gandhi Market Behind Sajjaa Dhaam Bed Sheet Bed cover Show room Kolkata 7 lakh 4
Thank you for watching our channel Please subscribed and like our videos for more jobs opening. Thank You again.
#QAEngineers, #Bank, #Recruiter, #ITCompany, #DataEngineer, #Kolkata, #WestBengal, #India, #World,
0 notes
Text
What is Django for beginners.
What is Django for Beginners?
Django is a high-level web framework for Python that encourages rapid development and clean, pragmatic design. It was created to help developers build web applications quickly and efficiently, allowing them to focus on writing code rather than dealing with the complexities of web development. For beginners, Django offers a powerful yet accessible way to learn the fundamentals of web development while building real-world applications.
Understanding Django
At its core, Django is designed to simplify the process of building web applications. It follows the Model-View-Template (MVT) architectural pattern, which separates the application into three interconnected components:
Model: This component handles the data and business logic. It defines the structure of the data, including the fields and behaviors of the data you’re storing. In Django, models are defined as Python classes, and they interact with the database to create, read, update, and delete records.
View: The view is responsible for processing user requests and returning the appropriate response. It acts as a bridge between the model and the template, retrieving data from the model and passing it to the template for rendering.
Template: Templates are used to define the presentation layer of the application. They are HTML files that can include dynamic content generated by the view. Django’s templating engine allows you to create reusable components and maintain a clean separation between the presentation and business logic.
Key Features of Django
Django comes with a plethora of features that make it an excellent choice for beginners:
Batteries Included: Django is often described as a "batteries-included" framework because it comes with a wide range of built-in features. This includes an admin panel, user authentication, form handling, and security features, which means you can get started quickly without needing to install additional packages.
Robust Security: Security is a top priority in Django. The framework provides built-in protections against common web vulnerabilities such as SQL injection, cross-site scripting (XSS), and cross-site request forgery (CSRF). This allows beginners to focus on building their applications without worrying about security issues.
Scalability: Django is designed to handle high-traffic applications. Its architecture allows for easy scaling, making it suitable for both small projects and large-scale applications. As your application grows, Django can accommodate increased traffic and data without significant changes to the codebase.
Versatile Database Support: Django supports multiple database backends, including SQLite, PostgreSQL, MySQL, and Oracle. This flexibility allows beginners to choose the database that best fits their needs and easily switch between them if necessary.
Strong Community and Documentation: Django has a large and active community, which means there are plenty of resources available for beginners. The official documentation is comprehensive and well-structured, making it easy to find information and learn how to use the framework effectively.
Benefits of Using Django for Beginners
Ease of Learning: Django’s clear and consistent design makes it easy for beginners to grasp the concepts of web development. The framework’s use of Python, a language known for its readability and simplicity, further lowers the barrier to entry.
Rapid Development: With Django, you can quickly build and deploy web applications. The framework’s built-in features and tools streamline the development process, allowing you to focus on writing code rather than dealing with repetitive tasks.
Community Support: As a beginner, having access to a supportive community can be invaluable. Django’s community is welcoming and offers numerous tutorials, forums, and resources to help you learn and troubleshoot issues.
Portfolio Development: Learning Django allows you to build real-world applications that you can showcase in your portfolio. This is particularly beneficial if you’re looking to enter the job market as a web developer, as having practical experience can set you apart from other candidates.
Long-Term Viability: Django is a mature framework that has been around since 2005. It is actively maintained and updated, ensuring that it remains relevant in the ever-evolving landscape of web development. By learning Django, you are investing in a skill that will be valuable for years to come.
Getting Started with Django
If you’re a beginner looking to dive into Django, here’s a simple roadmap to get you started:
Install Python: Since Django is a Python framework, the first step is to ensure you have Python installed on your machine. You can download it from the official Python website.
Set Up a Virtual Environment: It’s a good practice to create a virtual environment for your Django projects. This keeps your project dependencies isolated from other projects. You can use tools like venv or virtualenv to create a virtual environment.
Install Django: Once your virtual environment is set up, you can install Django using pip, Python’s package manager. Run the command pip install django in your terminal to get started.
Create a New Project: Use Django’s command-line tool to create a new project. Run django-admin startproject projectname to generate the necessary files and directory structure.
Run the Development Server: Navigate to your project directory and run the command python manage.py runserver. This will start a local development server, allowing you to view your application in your web browser.
Build Your First App: Django encourages a modular approach to development. You can create individual applications within your project using the command python manage.py startapp appname. From there, you can define models, views, and templates to build your application.
Explore Tutorials and Resources: Take advantage of the wealth of tutorials, documentation, and online courses available for Django. Websites like Django’s official documentation, YouTube, and platforms like Udemy and Coursera offer valuable learning materials.
Conclusion
In summary, Django is an excellent choice for beginners looking to learn web development. Its powerful features, robust security, and supportive community make it an ideal framework for building web applications. By understanding the fundamentals of Django and following a structured learning path, you can quickly gain the skills needed to create dynamic, data-driven websites. Whether you’re looking to build a personal project, enhance your portfolio, or start a career in web development, Django provides the tools and resources to help you succeed.
0 notes
Text
Beyond the Buzzword: Your Roadmap to Gaining Real Knowledge in Data Science

Data science. It's a field bursting with innovation, high demand, and the promise of solving real-world problems. But for newcomers, the sheer breadth of tools, techniques, and theoretical concepts can feel overwhelming. So, how do you gain real knowledge in data science, moving beyond surface-level understanding to truly master the craft?
It's not just about watching a few tutorials or reading a single book. True data science knowledge is built on a multi-faceted approach, combining theoretical understanding with practical application. Here’s a roadmap to guide your journey:
1. Build a Strong Foundational Core
Before you dive into the flashy algorithms, solidify your bedrock. This is non-negotiable.
Mathematics & Statistics: This is the language of data science.
Linear Algebra: Essential for understanding algorithms from linear regression to neural networks.
Calculus: Key for understanding optimization algorithms (gradient descent!) and the inner workings of many machine learning models.
Probability & Statistics: Absolutely critical for data analysis, hypothesis testing, understanding distributions, and interpreting model results. Learn about descriptive statistics, inferential statistics, sampling, hypothesis testing, confidence intervals, and different probability distributions.
Programming: Python and R are the reigning champions.
Python: Learn the fundamentals, then dive into libraries like NumPy (numerical computing), Pandas (data manipulation), Matplotlib/Seaborn (data visualization), and Scikit-learn (machine learning).
R: Especially strong for statistical analysis and powerful visualization (ggplot2). Many statisticians prefer R.
Databases (SQL): Data lives in databases. Learn to query, manipulate, and retrieve data efficiently using SQL. This is a fundamental skill for any data professional.
Where to learn: Online courses (Xaltius Academy, Coursera, edX, Udacity), textbooks (e.g., "Think Stats" by Allen B. Downey, "An Introduction to Statistical Learning"), Khan Academy for math fundamentals.
2. Dive into Machine Learning Fundamentals
Once your foundation is solid, explore the exciting world of machine learning.
Supervised Learning: Understand classification (logistic regression, decision trees, SVMs, k-NN, random forests, gradient boosting) and regression (linear regression, polynomial regression, SVR, tree-based models).
Unsupervised Learning: Explore clustering (k-means, hierarchical clustering, DBSCAN) and dimensionality reduction (PCA, t-SNE).
Model Evaluation: Learn to rigorously evaluate your models using metrics like accuracy, precision, recall, F1-score, AUC-ROC for classification, and MSE, MAE, R-squared for regression. Understand concepts like bias-variance trade-off, overfitting, and underfitting.
Cross-Validation & Hyperparameter Tuning: Essential techniques for building robust models.
Where to learn: Andrew Ng's Machine Learning course on Coursera is a classic. "Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow" by Aurélien Géron is an excellent practical guide.
3. Get Your Hands Dirty: Practical Application is Key!
Theory without practice is just information. You must apply what you learn.
Work on Datasets: Start with well-known datasets on platforms like Kaggle (Titanic, Iris, Boston Housing). Progress to more complex ones.
Build Projects: Don't just follow tutorials. Try to solve a real-world problem from start to finish. This involves:
Problem Definition: What are you trying to predict/understand?
Data Collection/Acquisition: Where will you get the data?
Exploratory Data Analysis (EDA): Understand your data, find patterns, clean messy parts.
Feature Engineering: Create new, more informative features from existing ones.
Model Building & Training: Select and train appropriate models.
Model Evaluation & Tuning: Refine your model.
Communication: Explain your findings clearly, both technically and for a non-technical audience.
Participate in Kaggle Competitions: This is an excellent way to learn from others, improve your skills, and benchmark your performance.
Contribute to Open Source: A great way to learn best practices and collaborate.
4. Specialize and Deepen Your Knowledge
As you progress, you might find a particular area of data science fascinating.
Deep Learning: If you're interested in image recognition, natural language processing (NLP), or generative AI, dive into frameworks like TensorFlow or PyTorch.
Natural Language Processing (NLP): Understanding text data, sentiment analysis, chatbots, machine translation.
Computer Vision: Image recognition, object detection, facial recognition.
Time Series Analysis: Forecasting trends in data that evolves over time.
Reinforcement Learning: Training agents to make decisions in an environment.
MLOps: The engineering side of data science – deploying, monitoring, and managing machine learning models in production.
Where to learn: Specific courses for each domain on platforms like deeplearning.ai (Andrew Ng), Fast.ai (Jeremy Howard).
5. Stay Updated and Engaged
Data science is a rapidly evolving field. Lifelong learning is essential.
Follow Researchers & Practitioners: On platforms like LinkedIn, X (formerly Twitter), and Medium.
Read Blogs and Articles: Keep up with new techniques, tools, and industry trends.
Attend Webinars & Conferences: Even virtual ones can offer valuable insights and networking opportunities.
Join Data Science Communities: Online forums (Reddit's r/datascience), local meetups, Discord channels. Learn from others, ask questions, and share your knowledge.
Read Research Papers: For advanced topics, dive into papers on arXiv.
6. Practice the Art of Communication
This is often overlooked but is absolutely critical.
Storytelling with Data: You can have the most complex model, but if you can't explain its insights to stakeholders, it's useless.
Visualization: Master tools like Matplotlib, Seaborn, Plotly, or Tableau to create compelling and informative visualizations.
Presentations: Practice clearly articulating your problem, methodology, findings, and recommendations.
The journey to gaining knowledge in data science is a marathon, not a sprint. It requires dedication, consistent effort, and a genuine curiosity to understand the world through data. Embrace the challenges, celebrate the breakthroughs, and remember that every line of code, every solved problem, and every new concept learned brings you closer to becoming a truly knowledgeable data scientist. What foundational skill are you looking to strengthen first?
1 note
·
View note
Text
Top Australian Universities for Cloud Computing and Big Data
In the age of digital transformation, data is the new oil; cloud computing is the infrastructure fuelling its refining. Big data and cloud computing together have created a dynamic ecosystem for digital services, business intelligence, and innovation generation. As industries shift towards cloud-first policies and data-driven decision-making, the demand for qualified individuals in these areas has increased. Known for its strong academic system and industry-aligned education, Australia offers excellent opportunities for foreign students to concentrate in Cloud Computing and Big Data. This post will examine the top Australian universities leading the way in these technical domains.
Why Study Cloud Computing and Big Data in Australia?
Ranked globally, Australia's universities are well-equipped with modern research tools, industry ties, and hands-on learning environments. Here are some fascinating reasons for learning Cloud Computing and Big Data in Australia:
Global Recognition:Ranked among the top 100 globally, Australian universities offer degrees recognised all around.
Industry Integration: Courses typically include capstone projects and internships as well as research collaborations with tech behemoths such as Amazon Web Services (AWS), Google Cloud, Microsoft Azure, and IBM.
High Employability: Graduates find decent employment in sectors including government, telecommunications, healthcare, and finance.
Post-Study Work Opportunities:Australia offers post-study work visas allowing foreign graduates to gain practical experience in the country.
Core Topics Covered in Cloud Computing and Big Data Courses
Courses in these fields typically cover:
Cloud Architecture & Security
Distributed Systems & Virtualization
Big Data Analytics
Machine Learning
Data Warehousing
Cloud Services (AWS, Google Cloud, Azure)
DevOps & Infrastructure Automation
Real-Time Data Processing (Apache Spark, Kafka)
Python, R, SQL, and NoSQL Databases
Top Australian Universities for Cloud Computing and Big Data
1. University of Melbourne
The University of Melbourne offers courses such the Master of Data Science and Master of Information Technology with a Cloud Computing emphasis. Renowned for its research excellence and global standing, the university emphasises a balance between fundamental knowledge and pragmatic cloud infrastructure training. Students benefit from close relationships with industry, including projects with AWS and Google Cloud, all run from its Parkville campus in Melbourne
2. University of Sydney
Emphasising Cloud Computing and Data Management, the University of Sydney provides the Master of Data Science and the Master of Information Technology. Its comprehensive course provides students information in data mining, architecture, and analytics. Internships and cooperative research in the heart of Sydney's Camperdown campus supported by the Sydney Informatics Hub allow students to engage with industry.
3. Monash University
Monash University offers a Master of Data Science as well as a Master of Information Technology concentrating in Enterprise Systems and Cloud Computing. Known for its multidisciplinary and practical approach, Monash mixes cloud concepts with artificial intelligence, cybersecurity, and IoT. Students located at the Melbourne Clayton campus have access to modern laboratories and industry-aligned projects.
4. University of New South Wales (UNSW Sydney)
University of New South Wales (UNSW Sydney) students can choose either the Master of Data Science and Decisions or the Master of IT. Under a curriculum covering distributed systems, networking, and scalable data services, UNSW provides practical training and close ties with Microsoft, Oracle, and other world players. The Kensington campus keeps a vibrant tech learning environment.
5. Australian National University (ANU)
The Australian National University (ANU), based in Canberra, offers the Master of Computing and the Master of Machine Learning and Computer Vision, both addressing Big Data and cloud tech. ANU's strength lies in its research-driven approach and integration of data analysis into scientific and governmental applications. Its Acton campus promotes high-level research with a global vi
6. University of Queensland (UQ)
The University of Queensland (UQ) offers the Master of Data Science as well as the Master of Computer Science with a concentration in Cloud and Systems Programming. UQ's courses are meant to include large-scale data processing, cloud services, and analytics. The St. Lucia campus in Brisbane also features innovation centres and startup incubators to enable students develop useful ideas.
7. RMIT University
RMIT University provides the Master of Data Science and the Master of IT with Cloud and Mobile Computing as a specialisation. RMIT, an AWS Academy member, places great importance on applied learning and digital transformation and provides cloud certifications in its courses. Students learn in a business-like environment at the centrally located Melbourne City campus.
8. University of Technology Sydney (UTS)
University of Technology Sydney (UTS) sets itself apart with its Master of Data Science and Innovation and Master of IT with Cloud Computing specialisation. At UTS, design thinking and data visualisation receive significant attention. Located in Ultimo, Sydney, the university features a "Data Arena" allowing students to interact with big-scale data sets visually and intuitively.
9. Deakin University
Deakin University offers a Master of Data Science as well as a Master of Information Technology with Cloud and Mobile Computing. Deakin's courses are flexible, allowing on-campus or online study. Its Burwood campus in Melbourne promotes cloud-based certifications and wide use of technologies including Azure and Google Cloud in course delivery.
10. Macquarie University
Macquarie University provides the Master of Data Science and the Master of IT with a Cloud Computing and Networking track. Through strong integration of cloud environments and scalable systems, the Macquarie Data Science Centre helps to foster industry cooperation. The North Ryde campus is famous for its research partnerships in smart infrastructure and public data systems.
Job Roles and Career Opportunities
Graduates from these programs can explore a wide range of roles, including:
Cloud Solutions Architect
Data Scientist
Cloud DevOps Engineer
Big Data Analyst
Machine Learning Engineer
Cloud Security Consultant
Database Administrator (Cloud-based)
AI & Analytics Consultant
Top Recruiters in Australia:
Amazon Web Services (AWS)
Microsoft Azure
Google Cloud
IBM
Atlassian
Accenture
Commonwealth Bank of Australia
Deloitte and PwC
Entry Requirements and Application Process
While specifics vary by university, here are the general requirements:
Academic Qualification: Bachelor’s degree in IT, Computer Science, Engineering, or a related field.
English Proficiency: IELTS (6.5 or above), TOEFL, or PTE.
Prerequisites:Some courses might need knowledge of statistics or programming (Python, Java).
Documents NeededSOP, academic transcripts, CV, current passport, and letters of recommendation.
Intakes:
February and July are the most common intakes.
Final Thoughts
Given the growing global reliance on digital infrastructure and smart data, jobs in Cloud Computing and Big Data are not only in demand but also absolutely essential. Australian universities are driving this transformation by offering overseas students the chance to learn from the best, interact with real-world technologies, and boldly enter global tech roles. From immersive courses and knowledgeable professors to strong industry ties, Australia provides the ideal launchpad for future-ready tech professionals.
Clifton Study Abroad is an authority in helping students like you negotiate the challenging road of overseas education. Our experienced advisors are here to help you at every turn, from choosing the right university to application preparation to getting a student visa. Your future in technology starts here; let us help you in opening your perfect Cloud Computing and Big Data job.
Are you looking for the best study abroad consultants in Kochi
#study abroad#study in uk#study abroad consultants#study in australia#study in germany#study in ireland#study blog
0 notes
Text
Slingshots for a Spider
I recently finished (didn't take the test, I was just stumbling through the course, open mouthed and scared) the ineffable WEB-300: Advanced Web Attacks and Exploitation, from the magnanimous OffSec, which is the preparation course for the Offensive Security Web Expert certification (OSWE). The image is a very cool digital black widow spider, which makes sense, because the course is teaching you how to be an attacker on 'the web'.

As scared as I am of spiders, I am enamored by this course. Enough to stare at it for two years then finally take it and complete it over one grueling year. It covers things like: Blind SQL Injection - setting things up in a program called Burpsuite, to repeatedly try sending various things, then clicking a button, and seeing how a website answers, whether it gives us info or errors (which is more info!)


Authentication Bypass Exploitation - skirting around the steps that websites use to make sure you are who you say you are, like taking a 'reset password' click of a button, knowing some admin's email, and getting a database to spit out the token so we can get to the website to reset the password before the admin.



and Server-Side Request Forgery - making a server (someone else's computer in charge of doing real work instead of messing around with a human) ask its connections and resources to get something for you.

Now I know what you're probably thinking: Holy cow, where to even start? If you're not thinking that, congratulations. If you are, I've the answer: Tools. No spider is eating flies without sensing, lurking, biting... this metaphor to say: No one's doing it by hand with no help.
So what tools are helpful? How do you know what's good, what's useful, what's a dime a dozen, what's only going to do part of what you want versus all of it...

Luckily the fan favorites are famous for a reason. Just about anything you'd need is already downloaded into Kali Linux, which is jam packed with much, much more than the average hacker even needs!
Tools are dependent on what you need to do. For this class we need to inspect web traffic, recover source code, analyze said code of source, and debug things remotely.
Inspecting web traffic covers SSL / TLS and HTTP. SSL is Secure Sockets Layer and TLS is Transport Layer Security. These are literally just protocols (rules! internet rules that really smart people spent a lot of time figuring out) that encrypts traffic (mixes and chops and surrounds your communication, to keep it safe and secure). HTTP is the hypertext transfer protocol, which is another set of rules that figures out how information is going to travel between devices, like computers, web servers, phones, etc.

But do you always follow the rules? Exactly. Even by accident, a lot can fall through the cracks or go wrong. Being able to see *exactly* what's happening is pivotal in *taking advantage* of what's not dotting the i's and crossing the t's.
Possibly the most famous tool for web hacking, and the obvious choice for inspecting web traffic, is Burp Suite. It gathers info, can pause in the middle of talking to websites and connections that usually happen behind the scenes in milliseconds, like manipulating HTTP requests. You can easily compare changes, decode, the list goes on.


Decompiling source code is the one where you could find a million things that all do very specific things. For example dnSpy can debug and edit .NET assemblies, like .exe or .dll files that usually *run*, and don't get cracked open and checked inside. At least not by a normal user. .NET binaries are easier to convert back to something readable because it uses runtime compiling, rather than compiling during assembly. All you have to do is de-compile. It's the difference between figuring out what's in a salad and what's in a baked loaf of bread. One's pretty easy to de-compile. The other, you'd probably not be able to guess, unless you already knew, that there are eggs in it! dnSpy decompiles assemblies so you can edit code, explore, and you can even add more features via dnSpy plugins.


Another type of code objects useful to analyze are Java ARchive or JAR files. Another decompiler that's good for JAR files is JD-GUI, which lets you inspect source code and Java class files so you can figure out how things work.


Analyzing source code is another act that can come with a lot of options. Data enters an application through a source. It's then used or it acts on its own in a 'sink'. We can either start at the sink (bottom-up approach) or with the sources (top-down approach). We could do a hybrid of these or even automate code analysis to snag low-hanging fruit and really balance between time, effort and quality. But when you have to just *look* at something with your *eyes*, most people choose VSCode. VSCode can download an incredible amount of plug ins, like remote ssh or kubernetes, it can push and pull to gitlab, examine hundreds of files with ease, search, search and replace... I could go on!

Last need is remote debugging, which really shows what an application is doing during runtime (when it's running!). Debugging can go step-by-step through huge amalgamations using breakpoints, which can continue through steps, step over a step, step INTO a step (because that step has a huge amalgamation of steps inside of it too, of course it does!), step out of that step, restart from the beginning or from a breakpoint, stop, or hot code replace. And the best part? VSCode does this too!

Remote debugging lets us debug a running process. All we need is access to the source code and debugger port on whatever remote system we happen to be working in.
Easy, right? Only a few tools and all the time in the world... WEB-300 was mostly whitebox application security, research, and learning chained attack methods. For example, you'd do three or seven steps, which incorporate two or four attacks, rather than just one. It's more realistic, as just one attack usually isn't enough to fell a giant. And here there be giants. Worry not: we've got some slingshots now.
The next step is seeing if we can get them to work!

Useful links:
(PortSwigger Ltd., 2020), https://portswigger.net/burp/documentation
(DNN Corp., 2020), https://www.dnnsoftware.com/
(0xd4d, 2020), https://github.com/0xd4d/dnSpy
(ICSharpCode , 2020), https://github.com/icsharpcode/ILSpy
(MicroSoft, 2021), https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/compiler-options/command-line-building-with-csc-exe
(Wikipedia, 2021), https://en.wikipedia.org/wiki/Cross-reference
(Wikipedia, 2019), https://en.wikipedia.org/wiki/Breakpoint
(Oracle, 2020), https://docs.oracle.com/javase/tutorial/deployment/jar/manifestindex.html
(Wikipedia, 2021), https://en.wikipedia.org/wiki/Integrated_development_environment
(Microsoft, 2022), https://code.visualstudio.com/(Wikipedia, 2021), https://en.wikipedia.org/wiki/False_positives_and_false_negatives
(Oracle, 2021), https://docs.oracle.com/javase/8/docs/technotes/guides/jpda/conninv.html#Invocation
0 notes
Text
DSC 450: Database Processing for Large-Scale Analytics Assignment Module 5
Part 1 Using the company.sql database (posted in with this assignment), write the following SQL queries. Find the names of all employees who are directly supervised by ‘Franklin T Wong’ (you cannot use Franklin’s SSN value in the query). For each project, list the project name, project number, and the total hours per week (by all employees) spent on that project. For each department,…
0 notes
Text
SAS Tutorial for Researchers: Streamlining Your Data Analysis Process
Researchers often face the challenge of managing large datasets, performing complex statistical analyses, and interpreting results in meaningful ways. Fortunately, SAS programming offers a robust solution for handling these tasks. With its ability to manipulate, analyze, and visualize data, SAS is a valuable tool for researchers across various fields, including social sciences, healthcare, and business. In this SAS tutorial, we will explore how SAS programming can streamline the data analysis process for researchers, helping them turn raw data into meaningful insights.
1. Getting Started with SAS for Research
For researchers, SAS programming can seem intimidating at first. However, with the right guidance, it becomes an invaluable tool for data management and analysis. To get started, you need to:
Understand the SAS Environment: Familiarize yourself with the interface, where you'll be performing data steps, running procedures, and viewing output.
Learn Basic Syntax: SAS uses a straightforward syntax where each task is organized into steps (Data steps and Procedure steps). Learning how to structure these steps is the foundation of using SAS effectively.
2. Importing and Preparing Data
The first step in any analysis is preparing your data. SAS makes it easy to import data from a variety of sources, such as Excel files, CSVs, and SQL databases. The SAS tutorial for researchers focuses on helping you:
Import Data: Learn how to load data into SAS using commands like PROC IMPORT.
Clean Data: Clean your data by removing missing values, handling outliers, and transforming variables as needed.
Merge Datasets: Combine multiple datasets into one using SAS’s MERGE or SET statements.
Having clean, well-organized data is crucial for reliable results, and SAS simplifies this process with its powerful data manipulation features.
3. Conducting Statistical Analysis with SAS
Once your data is ready, the next step is performing statistical analysis. SAS offers a wide array of statistical procedures that researchers can use to analyze their data:
Descriptive Statistics: Calculate basic statistics like mean, median, standard deviation, and range to understand your dataset’s characteristics.
Inferential Statistics: Perform hypothesis tests, t-tests, ANOVA, and regression analysis to make data-driven conclusions.
Multivariate Analysis: SAS also supports more advanced techniques, like factor analysis and cluster analysis, which are helpful for identifying patterns or grouping similar observations.
This powerful suite of statistical tools allows researchers to conduct deep, complex analyses without the need for specialized software
4. Visualizing Results
Data visualization is an essential part of the research process. Communicating complex results clearly can help others understand your findings. SAS includes a variety of charting and graphing tools that can help you present your data effectively:
Graphs and Plots: Create bar charts, line graphs, histograms, scatter plots, and more.
Customized Output: Use SAS’s graphical procedures to format your visualizations to suit your presentation or publication needs.
These visualization tools allow researchers to present data in a way that’s both understandable and impactful.
5. Automating Research Workflows with SAS
Another benefit of SAS programming for researchers is the ability to automate repetitive tasks. Using SAS’s macro functionality, you can:
Create Reusable Code: Build macros for tasks you perform frequently, saving time and reducing the chance of errors.
Automate Reporting: Automate the process of generating reports, so you don’t have to manually create tables or charts for every analysis.
youtube
Automation makes it easier for researchers to focus on interpreting results and less on performing routine tasks.
Conclusion
The power of SAS programming lies in its ability to simplify complex data analysis tasks, making it a valuable tool for researchers. By learning the basics of SAS, researchers can easily import, clean, analyze, and visualize data while automating repetitive tasks. Whether you're analyzing survey data, clinical trial results, or experimental data, SAS has the tools and features you need to streamline your data analysis process. With the help of SAS tutorials, researchers can quickly master the platform and unlock the full potential of their data.
#sas tutorial#sas tutorial for beginners#sas programming tutorial#SAS Tutorial for Researchers#Youtube
0 notes
Text
Top Vulnerability Assessment Tools to Secure Your Digital Assets
Cyberattacks are a reality in today's linked world that should not be neglected. Organizations that fail to recognize the magnitude of such risks threaten substantial reputational, financial, and legal consequences. As a result, they are not only a nightmare for end users but also a serious issue for enterprises.
But the million-plus query is, what are the main reasons for cyberattacks? Security experts declare that the primary causes of cyberattacks are social engineering, human errors, and vulnerabilities. While you can control the former two aspects with stronger security protocols and policies, vulnerabilities remain a constant threat.
Attackers frequently seek the flaws in targeted systems or apps because they provide the best potential to breach their security. Attackers can use vulnerabilities to carry out a variety of attacks, including cross-site scripting, SQL injection, session hijacking, and more.
Organizations require a thorough vulnerability assessment program to manage associated risks. You may automate this process by using feature-rich technologies that aid in the detection, categorization, and prioritizing of vulnerabilities. These vulnerability assessment tools help speed up the entire procedure.
This blog seeks to provide a comprehensive overview of vulnerability assessments, how they function, and the best tools. Continue scrolling for more details.
Download the sample report of Market Share: https://qksgroup.com/download-sample-form/market-share-vulnerability-assessment-2023-worldwide-6988
What is Vulnerability Assessment?
QKS Group defines vulnerability assessment as a comprehensive solution that enables organizations to identify, evaluate, and prioritize vulnerabilities within their IT infrastructure. Utilizing advanced automated tools and manual inspection techniques, it scans systems, applications, and network resources to uncover security weaknesses. By providing detailed reports on identified vulnerabilities, it empowers IT teams to address and mitigate risks effectively. Vulnerability Assessment solutions help prevent potential breaches, reduce the attack surface, and enhance overall cybersecurity posture.
Functionality of Vulnerability Scanning Solutions
The functionality of vulnerability scanning systems is essential for every company that produces and maintains large volumes of data, which frequently includes sensitive information specific to that organization. Attackers may attempt to identify and exploit weaknesses in the organization's systems to get unauthorized access to private data. Vulnerability analysis discovers and assesses risky locations inside an organization's network. This includes using various tools to find vulnerabilities and producing reports on the findings.
The vulnerability assessment scanning process is typically composed of three main actions:
Identifying Active Devices: The first step in the scanning procedure is identifying active devices within the target network using diverse scanning methods.
Cataloging Services and Operating Systems: Following the identification of active hosts, the following action is to catalogue the open ports and services and authenticate the operating systems running on the identified systems.
Evaluating for Vulnerabilities: The last stage involves examining the selected services and operating systems for any known vulnerabilities.
Top Vulnerability Assessment Tools
Undoubtedly, you want to use the finest tool for assessing digital assets for vulnerabilities. Such a tool will provide precise data, faster scanning times, convenience of use, and several other advantages. It would be much better if they were free. This is what you'll receive with the tools listed below.
Rapid7
Rapid7, Inc. strives to build a safer digital world by simplifying and making cybersecurity more accessible. Rapid7's technology, research, and extensive strategic skills enable security professionals across the world to handle a modern attack surface. Rapid7's comprehensive security solutions assist over 11,000 clients in combining cloud risk management with threat detection and response to decrease attack surfaces and eradicate attacks quickly and accurately.
Tenable Nessus
Tenable is an exposure management company that identifies and closes cybersecurity holes that reduce corporate value, reputation, and trust. The company's AI-powered exposure management platform dramatically integrates security visibility, insight, and action across the attack surface, enabling contemporary companies to defend against assaults on IT infrastructure, cloud environments, critical infrastructure, and everything in between.
Holm Security VMP
Holm Security is a next-generation vulnerability management software supplier that focuses on thorough 360-degree inspection. The business specializes in helping enterprises with vulnerability detection, risk assessment, and remedial prioritization. This is realized for all assets across a company. The solution has three levels and offers all the tools required for smooth vulnerability management.
RidgeBot
Ridge Security offers a new solution for security testing with their product, RidgeBot, an Intelligent Penetration Testing Robot. RidgeBot uses complex ways to penetrate networks comparable to those employed by hackers. RidgeBot, once inserted into a system, hunts out, exploits, and documents any flaws it discovers. It functions within a set scope and can quickly adapt to extremely complicated structures. Ridge Security's products benefit business and web application teams, ISVs, government agencies, educational institutions, and any other party responsible for software security by allowing them to test their systems economically and efficiently.
WithSecure Elements
WithSecure was once known as F-Secure Business. IT service providers, MSSPs, and enterprises rely on us for results-driven cyber security that protects and empowers their operations. WithSecure's AI-driven security safeguards endpoints and cloud collaboration, and its intelligent detection and response capabilities are powered by specialists that identify business risks by actively scanning for threats and combating actual attacks.
Download the sample report of Market Forecast: https://qksgroup.com/download-sample-form/market-forecast-vulnerability-assessment-2024-2028-worldwide-7141
Growing Demand for Vulnerability Assessment Solutions Amid Rising Cyber Threats
The global market for Vulnerability Assessment solutions is expanding rapidly, driven by rising cyber threats and demanding regulatory requirements across sectors. Organizations across the world are rapidly investing in sophisticated Vulnerability Assessment technologies to strengthen their cybersecurity defenses, minimize risks, and maintain compliance with regulatory requirements such as GDPR, HIPAA, and PCI-DSS. The proliferation of cloud computing, IoT, and other digital technologies is driving up demand for these solutions, as organizations strive to secure their digital assets and maintain operational resilience in an increasingly linked world.
The future of the Vulnerability Assessment market on a global scale appears promising, marked by continuous technological innovations and a proactive approach to cybersecurity. As cyber-attacks become more sophisticated and pervasive, there is a growing emphasis on deploying advanced Vulnerability Assessment solutions that offer real-time insights through Market Share: Vulnerability Assessment, 2023, Worldwide" and "Market Forecast: Vulnerability Assessment, 2024-2028, Worldwide" reports by QKS Group and proactive threat management capabilities.
Incorporating artificial intelligence, machine learning, and automation into these solutions will play a vital role in increasing their efficacy and allowing enterprises to remain ahead of new risks. Furthermore, increased collaboration between the public and private sectors and rising organizational awareness of the importance of cybersecurity will drive global adoption of Vulnerability Assessment tools, ensuring a secure digital landscape for both businesses and consumers.
0 notes
Text
Easily Switch Your Tableau Dashboards to Power BI Using Pulse Convert
At Office Solution, we understand how important it is to have the right tools for your business intelligence (BI) needs. Many organizations start their data journey with Tableau, but as their requirements evolve, they often find Power BI to be a more cost-effective and flexible platform. However, moving dashboards from Tableau to Power BI manually can be a complex and time-consuming process. That’s where Pulse Convert comes in �� a smart, automated solution to easily switch your Tableau dashboards to Power BI without the headache of manual conversion.
Why Companies are Moving from Tableau to Power BI
There are several reasons why businesses are shifting from Tableau to Power BI:
Cost Efficiency: Power BI is included in many Microsoft packages, making it a more budget-friendly option for companies already using Microsoft tools.
Seamless Integration: Power BI works smoothly with Excel, Teams, SharePoint, and other Microsoft platforms, simplifying workflows.
Ease of Use: Power BI offers a user-friendly interface that both analysts and non-technical users find easy to navigate.
Scalability: Power BI’s cloud-based architecture allows businesses to scale their analytics as they grow.
Despite these benefits, companies often hesitate to migrate because converting dashboards manually from Tableau to Power BI is both tedious and error-prone. This is exactly why we created Pulse Convert — to make this transition effortless for you.
What is Pulse Convert?
Pulse Convert is a powerful tool designed by Office Solution to automate the process of converting Tableau dashboards to Power BI. Instead of starting from scratch, you can simply input your Tableau files, and Pulse Convert will translate them into Power BI reports — including visuals, layouts, and data connections.
With Pulse Convert, businesses can save weeks of effort and avoid costly manual errors. It ensures that your data visualizations retain their accuracy and appearance in Power BI.
Key Benefits of Using Pulse Convert
Here’s why businesses love Pulse Convert when making the switch:
1. Time-Saving Automation
Manually recreating Tableau dashboards in Power BI could take weeks, especially for teams with limited Power BI expertise. Pulse Convert reduces this process to just a few clicks, freeing your team to focus on analyzing data instead of recreating it.
2. Visual and Layout Consistency
Your Tableau dashboards were carefully designed to convey insights effectively. Pulse Convert preserves the design, colors, and visual layouts, ensuring your Power BI reports look familiar to your users.
3. Data Connection Mapping
Pulse Convert helps map your Tableau data sources to Power BI-compatible data sources, simplifying the data connection process. Whether you’re working with Excel files, SQL databases, or cloud data, Pulse Convert handles the translation seamlessly.
4. Error Reduction
Manual conversions are prone to human errors — missing filters, incorrect calculations, or layout shifts. Pulse Convert minimizes errors by automating the process with proven algorithms.
5. Cost-Effective Transition
Instead of hiring external consultants for expensive, time-intensive migration projects, Pulse Convert allows your internal team to handle the migration themselves — saving both time and money.
Who Should Use Pulse Convert?
Companies migrating from Tableau to Power BI to align with their Microsoft ecosystem.
BI Teams looking to standardize reporting tools across the organization.
IT Departments aiming to reduce software licensing costs by consolidating analytics tools.
Analysts and Data Professionals who want to focus on insights rather than technical migrations.
How Office Solution Helps You
At Office Solution, we’re more than just a software provider — we’re your trusted partner in digital transformation. With years of experience helping businesses simplify BI migrations, we know the common challenges companies face and have tailored Pulse Convert to address them directly.
From initial setup to ongoing support, Office Solution works with you to ensure a smooth, stress-free transition from Tableau to Power BI.
Ready to Switch from Tableau to Power BI?
Don’t let migration challenges hold your business back. With Pulse Convert, you can easily switch your Tableau dashboards to Power BI and unlock the full power of Microsoft’s ecosystem.
Contact Office Solution today to schedule a demo or start your free trial of Pulse Convert — and make your data migration seamless and stress-free.
Visit us : https://tableautopowerbimigration.com/
0 notes
Text
Microsoft Fabric data warehouse
Microsoft Fabric data warehouse
What Is Microsoft Fabric and Why You Should Care?
Unified Software as a Service (SaaS), offering End-To-End analytics platform
Gives you a bunch of tools all together, Microsoft Fabric OneLake supports seamless integration, enabling collaboration on this unified data analytics platform
Scalable Analytics
Accessibility from anywhere with an internet connection
Streamlines collaboration among data professionals
Empowering low-to-no-code approach
Components of Microsoft Fabric
Fabric provides comprehensive data analytics solutions, encompassing services for data movement and transformation, analysis and actions, and deriving insights and patterns through machine learning. Although Microsoft Fabric includes several components, this article will use three primary experiences: Data Factory, Data Warehouse, and Power BI.
Lake House vs. Warehouse: Which Data Storage Solution is Right for You?
In simple terms, the underlying storage format in both Lake Houses and Warehouses is the Delta format, an enhanced version of the Parquet format.
Usage and Format Support
A Lake House combines the capabilities of a data lake and a data warehouse, supporting unstructured, semi-structured, and structured formats. In contrast, a data Warehouse supports only structured formats.
When your organization needs to process big data characterized by high volume, velocity, and variety, and when you require data loading and transformation using Spark engines via notebooks, a Lake House is recommended. A Lakehouse can process both structured tables and unstructured/semi-structured files, offering managed and external table options. Microsoft Fabric OneLake serves as the foundational layer for storing structured and unstructured data Notebooks can be used for READ and WRITE operations in a Lakehouse. However, you cannot connect to a Lake House with an SQL client directly, without using SQL endpoints.
On the other hand, a Warehouse excels in processing and storing structured formats, utilizing stored procedures, tables, and views. Processing data in a Warehouse requires only T-SQL knowledge. It functions similarly to a typical RDBMS database but with a different internal storage architecture, as each table’s data is stored in the Delta format within OneLake. Users can access Warehouse data directly using any SQL client or the in-built graphical SQL editor, performing READ and WRITE operations with T-SQL and its elements like stored procedures and views. Notebooks can also connect to the Warehouse, but only for READ operations.
An SQL endpoint is like a special doorway that lets other computer programs talk to a database or storage system using a language called SQL. With this endpoint, you can ask questions (queries) to get information from the database, like searching for specific data or making changes to it. It’s kind of like using a search engine to find things on the internet, but for your data stored in the Fabric system. These SQL endpoints are often used for tasks like getting data, asking questions about it, and making changes to it within the Fabric system.
Choosing Between Lakehouse and Warehouse
The decision to use a Lakehouse or Warehouse depends on several factors:
Migrating from a Traditional Data Warehouse: If your organization does not have big data processing requirements, a Warehouse is suitable.
Migrating from a Mixed Big Data and Traditional RDBMS System: If your existing solution includes both a big data platform and traditional RDBMS systems with structured data, using both a Lakehouse and a Warehouse is ideal. Perform big data operations with notebooks connected to the Lakehouse and RDBMS operations with T-SQL connected to the Warehouse.
Note: In both scenarios, once the data resides in either a Lakehouse or a Warehouse, Power BI can connect to both using SQL endpoints.
A Glimpse into the Data Factory Experience in Microsoft Fabric
In the Data Factory experience, we focus primarily on two items: Data Pipeline and Data Flow.
Data Pipelines
Used to orchestrate different activities for extracting, loading, and transforming data.
Ideal for building reusable code that can be utilized across other modules.
Enables activity-level monitoring.
To what can we compare Data Pipelines ?
microsoft fabric data pipelines Data Pipelines are similar, but not the same as:
Informatica -> Workflows
ODI -> Packages
Dataflows
Utilized when a GUI tool with Power Query UI experience is required for building Extract, Transform, and Load (ETL) logic.
Employed when individual selection of source and destination components is necessary, along with the inclusion of various transformation logic for each table.
To what can we compare Data Flows ?
Dataflows are similar, but not same as :
Informatica -> Mappings
ODI -> Mappings / Interfaces
Are You Ready to Migrate Your Data Warehouse to Microsoft Fabric?
Here is our solution for implementing the Medallion Architecture with Fabric data Warehouse:
Creation of New Workspace
We recommend creating separate workspaces for Semantic Models, Reports, and Data Pipelines as a best practice.
Creation of Warehouse and Lakehouse
Follow the on-screen instructions to setup new Lakehouse and a Warehouse:
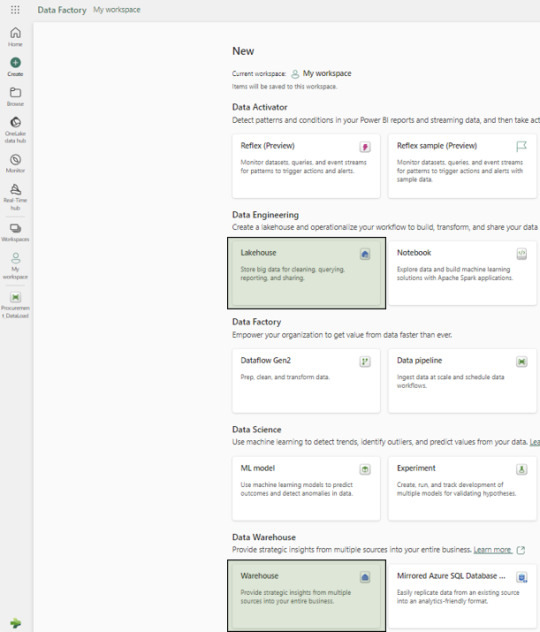
Configuration Setups
Create a configurations.json file containing parameters for data pipeline activities:
Source schema, buckets, and path
Destination warehouse name
Names of warehouse layers bronze, silver and gold – OdsStage,Ods and Edw
List of source tables/files in a specific format
Source System Id’s for different sources
Below is the screenshot of the (config_variables.json) :

File Placement
Place the configurations.json and SourceTableList.csv files in the Fabric Lakehouse.
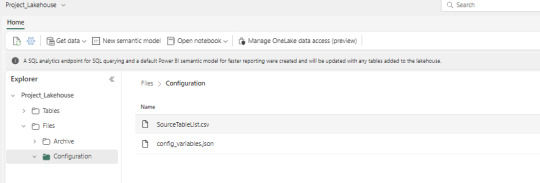
SourceTableList will have columns such as – SourceSystem, SourceDatasetId, TableName, PrimaryKey, UpdateKey, CDCColumnName, SoftDeleteColumn, ArchiveDate, ArchiveKey
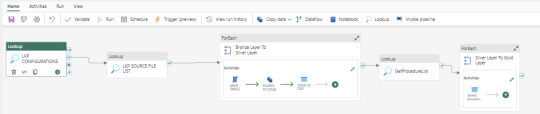
Data Pipeline Creation
Create a data pipeline to orchestrate various activities for data extraction, loading, and transformation. Below is the screenshot of the Data Pipeline and here you can see the different activities like – Lookup, ForEach, Script, Copy Data and Stored Procedure
Bronze Layer Loading
Develop a dynamic activity to load data into the Bronze Layer (OdsStage schema in Warehouse). This layer truncates and reloads data each time.
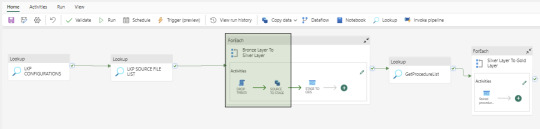
We utilize two activities in this layer: Script Activity and Copy Data Activity. Both activities receive parameterized inputs from the Configuration file and SourceTableList file. The Script activity drops the staging table, and the Copy Data activity creates and loads data into the OdsStage table. These activities are reusable across modules and feature powerful capabilities for fast data loading.
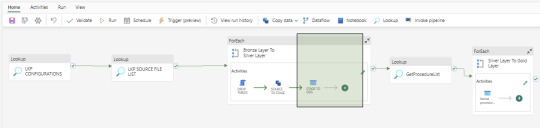
Silver Layer Loading
Establish a dynamic activity to UPSERT data into the Silver layer (Ods schema in Warehouse) using a stored procedure activity. This procedure takes parameterized inputs from the Configuration file and SourceTableList file, handling both UPDATE and INSERT operations. This stored procedure is reusable. At this time, MERGE statements are not supported by Fabric Warehouse. However, this feature may be added in the future.
Control Table Creation
Create a control table in the Warehouse with columns containing Sequence Numbers and Procedure Names to manage dependencies between Dimensions, Facts, and Aggregate tables. And finally fetch the values using a Lookup activity.
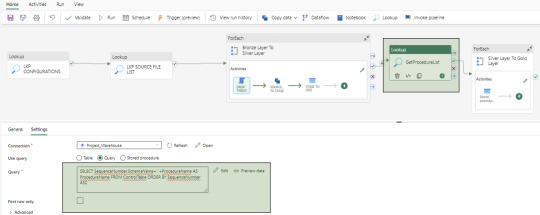
Gold Layer Loading
To load data into the Gold Layer (Edw schema in the warehouse), we develop individual stored procedures to UPSERT (UPDATE and INSERT) data for each dimension, fact, and aggregate table. While Dataflow can also be used for this task, we prefer stored procedures to handle the nature of complex business logic.

Dashboards and Reporting
Fabric includes the Power BI application, which can connect to the SQL endpoints of both the Lakehouse and Warehouse. These SQL endpoints allow for the creation of semantic models, which are then used to develop reports and applications. In our use case, the semantic models are built from the Gold layer (Edw schema in Warehouse) tables.
Upcoming Topics Preview
In the upcoming articles, we will cover topics such as notebooks, dataflows, lakehouse, security and other related subjects.
Conclusion
microsoft Fabric data warehouse stands as a potent and user-friendly data manipulation platform, offering an extensive array of tools for data ingestion, storage, transformation, and analysis. Whether you’re a novice or a seasoned data analyst, Fabric empowers you to optimize your workflow and harness the full potential of your data.
We specialize in aiding organizations in meticulously planning and flawlessly executing data projects, ensuring utmost precision and efficiency.
Curious and would like to hear more about this article ?
Contact us at [email protected] or Book time with me to organize a 100%-free, no-obligation call
Follow us on LinkedIn for more interesting updates!!
DataPlatr Inc. specializes in data engineering & analytics with pre-built data models for Enterprise Applications like SAP, Oracle EBS, Workday, Salesforce to empower businesses to unlock the full potential of their data. Our pre-built enterprise data engineering models are designed to expedite the development of data pipelines, data transformation, and integration, saving you time and resources.
Our team of experienced data engineers, scientists and analysts utilize cutting-edge data infrastructure into valuable insights and help enterprise clients optimize their Sales, Marketing, Operations, Financials, Supply chain, Human capital and Customer experiences.
0 notes
Text
PowerApps Training | Power Automate Training
PowerApps Search Function: Using 'Contains' for Better Results

PowerApps Training, The PowerApps Search Function is an essential tool for building efficient and user-friendly applications. This function empowers developers and users to find data quickly and easily by providing flexibility in how they search within an app. One of the most powerful features of the PowerApps Search Function is its ability to incorporate the Contains operator, which allows for partial matches and delivers more relevant search results.
In this article, we will explore how the PowerApps Search Function works, its benefits, and step-by-step guidance on using the Contains operator effectively. Whether you're a beginner or a seasoned developer, you'll discover actionable insights to enhance your PowerApps applications. Power Automate Training
What Is the PowerApps Search Function?
The PowerApps Search Function is used to filter records in a data source based on search criteria entered by the user. It provides a simple and effective way to build search capabilities into your app. For instance, users can type a keyword in a search bar, and the app will display matching results from a table, collection, or connected data source.
The PowerApps Search Function is particularly valuable because it supports case-insensitive searches, making it easier for users to find what they need without worrying about capitalization. Additionally, when combined with the Contains operator, it becomes even more powerful, allowing for partial matches and broader search possibilities.
Why Use the 'Contains' Operator with PowerApps Search Function?
The Contains operator enhances the flexibility of the PowerApps Search Function. Instead of requiring an exact match for a search term, Contains lets users search for records that include the term anywhere in the field. This functionality is ideal for scenarios where users might only know part of a name, description, or keyword. PowerApps Training
For example, imagine a scenario where you're building an app to search a customer database. A user searching for "Smith" can find records like "John Smith" or "Smithson Enterprises" without needing to type the exact match.
Some key benefits of using the Contains operator with the PowerApps Search Function include:
Improved User Experience: Users can find results even with incomplete information.
Faster Data Retrieval: Partial matches save time and reduce the frustration of unsuccessful searches.
Enhanced Flexibility: Works seamlessly across different types of data fields, such as names, descriptions, and IDs.
How to Use 'Contains' with PowerApps Search Function
Here’s a step-by-step guide to implementing the Contains operator with the PowerApps Search Function in your application:
Step 1: Set Up Your Data Source
First, ensure that your app is connected to a data source. This could be a SharePoint list, Excel table, or SQL database. For demonstration purposes, let's assume you're working with a collection named CustomerData. Power Automate Training
Step 2: Add a Search Bar
Add a Text Input control to your app and name it txtSearch. This will serve as the search bar where users can input their search terms.
Step 3: Configure the Search Functionality
To enable the PowerApps Search Function in your app, begin by setting up a mechanism for users to enter their search terms, such as a search bar or text input field. Link this search bar to your data source and specify the fields you want users to search through, such as names, emails, or phone numbers. This ensures that the app dynamically filters and displays relevant results based on the user’s input.
Step 4: Refine with 'Contains' for Partial Matches
To make your search feature more robust, utilize the Contains operator. This ensures that users can retrieve results even if they only provide partial information. For instance, a search for a partial name or keyword will match records containing that term anywhere in the relevant fields. By applying this approach, your app delivers more accurate and inclusive search results, enhancing the overall user experience.
Step 5: Test and Refine
Run your app and test the search functionality by entering different keywords. Adjust the fields in the formula as needed to optimize the search experience for your users.
Best Practices for Using PowerApps Search Function
To maximize the effectiveness of the PowerApps Search Function, consider these best practices:
Optimize Data Sources: Ensure your data sources are indexed and structured efficiently to improve search performance.
Limit Search Scope: Avoid searching across too many fields simultaneously, as this can slow down performance.
Provide Clear Instructions: Add placeholders or tooltips to the search bar to guide users on how to use the search function effectively.
Enhance Results Display: Use filters and sorting options to make search results more user-friendly.
Handle Empty Results: Add a message or visual indicator to inform users when no results are found.
Real-World Applications of PowerApps Search Function
The PowerApps Search Function is widely used across various industries. Here are a few examples:
Customer Relationship Management (CRM): Quickly search for customer details by name, email, or phone number.
Inventory Management: Find products based on partial names or descriptions.
Employee Directory: Locate employees in a database using their first or last name.
Event Management: Search for attendees based on registration details.
These applications demonstrate the versatility of the PowerApps Search Function, particularly when paired with the Contains operator.
Common Challenges and How to Overcome Them
While the PowerApps Search Function is powerful, it does come with some challenges:
Performance Issues with Large Data Sets: Searching large data sources can slow down app performance. Solution: Use delegable data sources and optimize your queries.
Complex Search Requirements: Advanced filtering may require combining multiple functions, such as Search, Filter, and Contains. Solution: Plan your formulas carefully and test extensively.
Case Sensitivity in Non-Delegable Functions: Although Search is case-insensitive, combining it with other functions may introduce case-sensitivity. Solution: Use Lower or Upper to normalize text.
Conclusion
The PowerApps Search Function is a game-changer for building dynamic, user-friendly apps. By integrating the Contains operator, you can elevate your app’s search capabilities, enabling users to find data more easily and efficiently. Whether you’re developing a CRM, an inventory tracker, or an employee directory, mastering the PowerApps Search Function is a must for delivering a superior user experience.
Start exploring the possibilities of the PowerApps Search Function today and see how it transforms your application’s functionality!
Visualpath is the Leading and Best Institute for learning in Hyderabad. We provide PowerApps and Power Automate Training. You will get the best course at an affordable cost.
Attend Free Demo
Call on – +91-9989971070
Blog: https://toppowerautomatetraining.blogspot.com/
What’s App: https://www.whatsapp.com/catalog/919989971070/
Visit: https://www.visualpath.in/online-powerapps-training.html
#PowerApps Training#Power Automate Training#PowerApps Training in Hyderabad#PowerApps Online Training#Microsoft PowerApps Training#PowerApps Training Course#PowerApps and Power Automate Training#Microsoft PowerApps Training Courses
1 note
·
View note